How to get notices from your college website using nodejs.

Ever wanted to build a notice app or creating a notification system for new notices for your college? But how to get real-time notices data? Not all colleges (not mine) provides an HTTP endpoint to get college notices. However, not to worry, we can use web scrapping to extract notices directly from the college website.
What is web scraping?
In simple words, web scraping means to extract data from websites. Read webharvy's article on web scraping to know more about it.
How are we going to extract notice data from the college website?
As an example, I will use my college's website. Notices on my college's website can be found here. We will be creating a simple Node JS script that reads the response from the college's noticeboard URL https://heritageit.edu/Notice.aspx and then parses the HTML response received and extract the notice data using simple DOM traversing/manipulation. For this, we will be using two npm libraries: GOT and cheerio.
Libraries we will use to get the notices from the college website
- GOT is a powerful library to make HTTP requests. We will be using it to get webpage data from the noticeboard URL.
- cheerio parses the HTML markup and returns a jquery object to manipulate and traverse the dom. We will be using it to extract notice data with simple dom traversing, the same as we do in the browser apps.
Let us examine the HTML markup of my college's notice webpage.
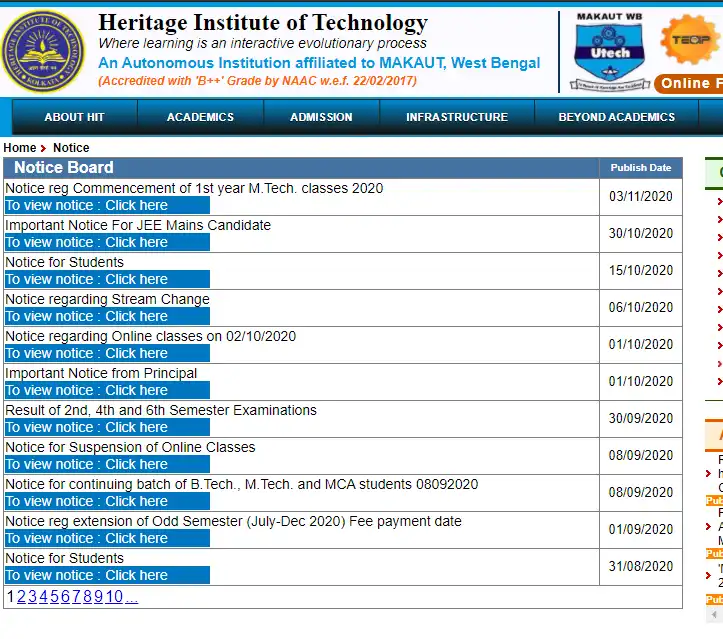
Before starting to code to get notices from the college website. We need to understand the HTML markup of the webpage. To see its source code, right-click anywhere over it and then click on "Inspect". You will find that whole notices data is wrapped in a table element with id "ctl00_ContentPlaceHolder1_GridView1". Check the image of the table element given below.
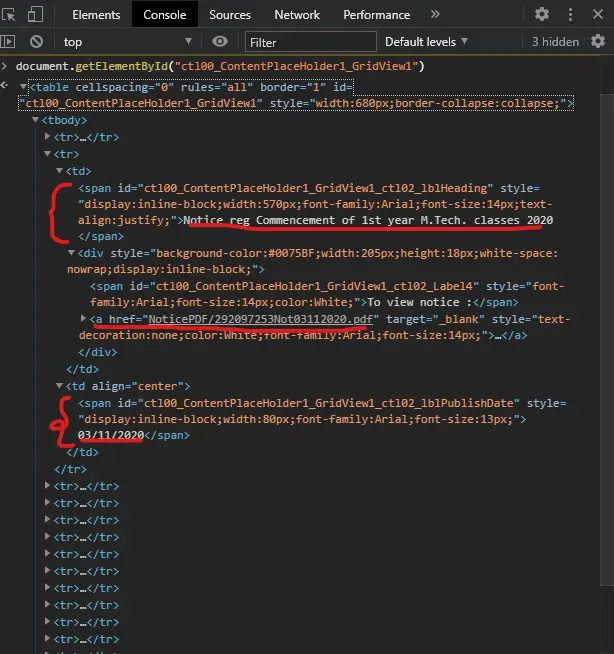
As you can see, each notice is wrapped in a tr element. Each tr element has two td child elements. The first td element has a span child element which contains the title of the notice and a div element. Again, the div element has an a element whose "href" attribute has the relative link to the notice pdf file. This was all about the first td child of the the tr element. Remember that each tr element wraps one notice.
After that, the second td child element of tr element has a span that contains the date of the notice. All this seems confusing, right? Check this image to visually understand what I have just explained.

The DOM hierarchy of table wrapping notices.
One more thing to be noticed in the source code is that not all tr element is for the notice. Like the first, tr contains heading for the table. Last tr contains the page numbers. We have to ignore these tr. I will explain how later.
The approach we are going to take to get the notice data from the college website.
Till now, we have understood the HTML markup of the table that contains notices data. After that, what we will do is get the list of all tr of the table with id "ctl00_ContentPlaceHolder1_GridView1". We will query from it, an a element that has the href attribute defined. See the tr hierarchy in the diagram above, there is only one a element. If this particular tr has valid notice data, then the URL in the "href" attribute of a must be a valid URL of notice's pdf file. If not, then we are going to ignore this tr. For a given valid tr:
- title: The span of the first td child of tr
- date: The span of the second td child of tr
- url: The href attribute of a element of tr.
The Code.
Setting up the project
I have hosted my project on Github. You can find it here. Or you can just follow the following steps. Create a folder called HeritageNotice and open that folder in VS Code (or editor of your choice).
Initialize npm.
npm init
Install GOT and cheerio.
npm install --save got cheerio
Create a file called index.js. Add the following code that reads the response from the Heritage Notice website and extracts notice data from it.
const cheerio = require('cheerio');
const got = require('got');
const BASE_URL = "https://www.heritageit.edu/";
const NOTICE_URL = "https://www.heritageit.edu/Notice.aspx";
//matches if the given relative URL is valid URL of notice pdf file or not
const matchNoticeUrl = val => {
return /NoticePDF\/[0-9]+NOT[0-9]+.pdf/i.test(val);
}
//Reads data from the heritage website
const getData = async () => {
//creates a get request and returns the response
const response = await got(NOTICE_URL);
//cheerio parses the html and returns a jquery object
//to traverse and manipulate the DOM.
const $ = cheerio.load(response.body);
//This query returns list of all the <tr> child of <table>
//with id ctl00_ContentPlaceHolder1_GridView1
const trows = $('table#ctl00_ContentPlaceHolder1_GridView1 tr').toArray();
const notices = [];
for(let i = 0,tr,name,date; i < trows.length; i++){
tr = $(trows[i]);
//finds the child <a> of current <tr>
relUrl = $(tr).find('a').attr('href');
//returns the text of <span> of the first <td> child of current <tr>
name = $((tr).find("td").get(0))
.find('span').html();
//returns the text of <span> of the second <td> child of current <tr>
date = $($(tr).find("td").get(1))
.find("span").html();
//if the relUrl is not a valid relative URL of notice PDF file
//Then, this tr does not wrap a notice data
if(matchNoticeUrl(relUrl)){
notices.push({
url: BASE_URL+relUrl,
relUrl,
name,
date
});
}
}
return notices;
}
exports.getData = getData;
Create a new file called scarp.js and add the following code that calls our getData() function.
const { getData } = require("./index");
getData()
.then(data=>{
console.log(data);
})
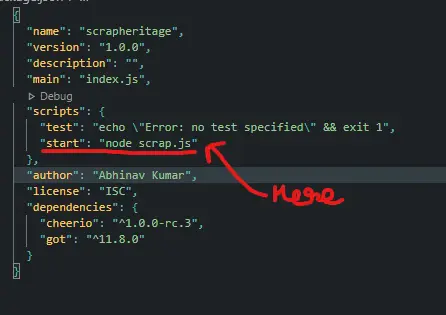
Open the package.json and add the following line to the script's part.
"start": "node scrap.js"
The package.json file should now look something like this:
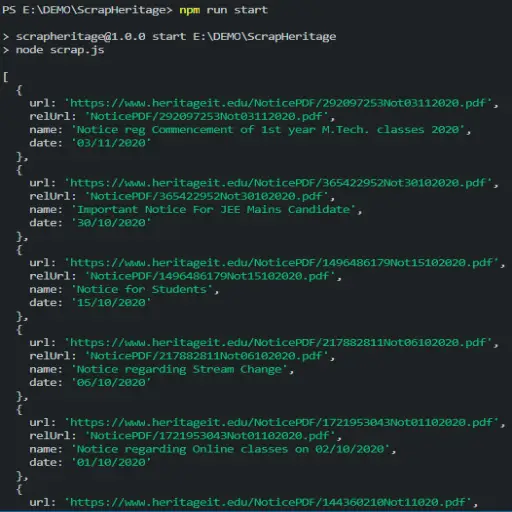
Now run the script.
npm run start
The program will read the HTML response from the Heritage notice website. After that, it will parse the HTML, extract the notices, and finally print them.
The conclusion
For this article, I have taken an example of my college website. But, you can examine the HTML markup of your college's website and get notices from the college website. After that, you can create an HTTP endpoint and read notice data from your app using simple HTTP requests. Surely, this approach may not be the best approach. If you have another approach or have any questions, just drop a comment below. Happy coding!
Links
Github project link: https://github.com/abhinavkrin/HeritageNoticeREST
I have deployed a cloud function that returns notices in JSON: https://us-central1-development-and-test-292807.cloudfunctions.net/getNotices?page=1